
![[Paper Review]: Expanding Language-Image Pretrained Models for General Video Recognition [ECCV, 2022]](images/jeongchoel/xclip/overview.png)

Introduction
- Video recognition
- 과거에는 CNN, 최근에는 Transformer에 기반하여 video recognition은 상당한 발전을 이룸
- 그러나 대부분의 video recognition 연구들은 close-set learning 설정에서 수행됨
- close-set: training category 및 test category가 동일하며 한정적인 설정
- open-set (zero-shot) video recognition 연구가 필요함
- Contrastive language-image pre-traning (CLIP)
- 최근, 대형 contrative language-image pre-trained model은 이러한 문제를 효과적으로 해결
- 핵심은 visual-language representation을 web-scale image-text data를 사용하여 자연어 supervision으로 학습하는 것
- 사전학습 후, 자연어는 downstream tasks (zero/few-shot)의 supervision으로 사용됨
- Expanding languge-image pre-trained model for video
- 일부 연구들은 video-text data 기반 pre-training을 연구하였으나 매우 어려움
- 이는 image보다 큰 용량의 video data와 GPU 자원을 요구함
- 실현 가능한 해법은 launge-image pre-trained model을 비디오에 직접 적용하는 것
- 이에 대하여 고려할 사항은 2가지
- temporal information을 어떻게 다룰 것인가?
- video에 대한 discriminative text representation을 어떻게 획득할 것인가?
- 일부 연구들은 video-text data 기반 pre-training을 연구하였으나 매우 어려움
- Leveraging temporal information
- Cross-frame communication transformer
- frame 간 정보를 교환
- Multi-frame integration transformer
- frame-level representation을 video-level representation으로 변환 (temporal pooling)
- Cross-frame communication transformer
- Acquiring discriminative text representation
- video-specific prompting scheme
- video representation을 semantic labels에 융합하여 text prompting을 강화
- ex) “in the water”와 같은 추가적인 비디오 정보는 “swimming”과 “running” 같은 행동들을 더 쉽게 구분할 수 있게 함
- 고정적인 prompting이 아닌 learnable mechanism을 제안
- video representation을 semantic labels에 융합하여 text prompting을 강화
- video-specific prompting scheme
Proposed Methods
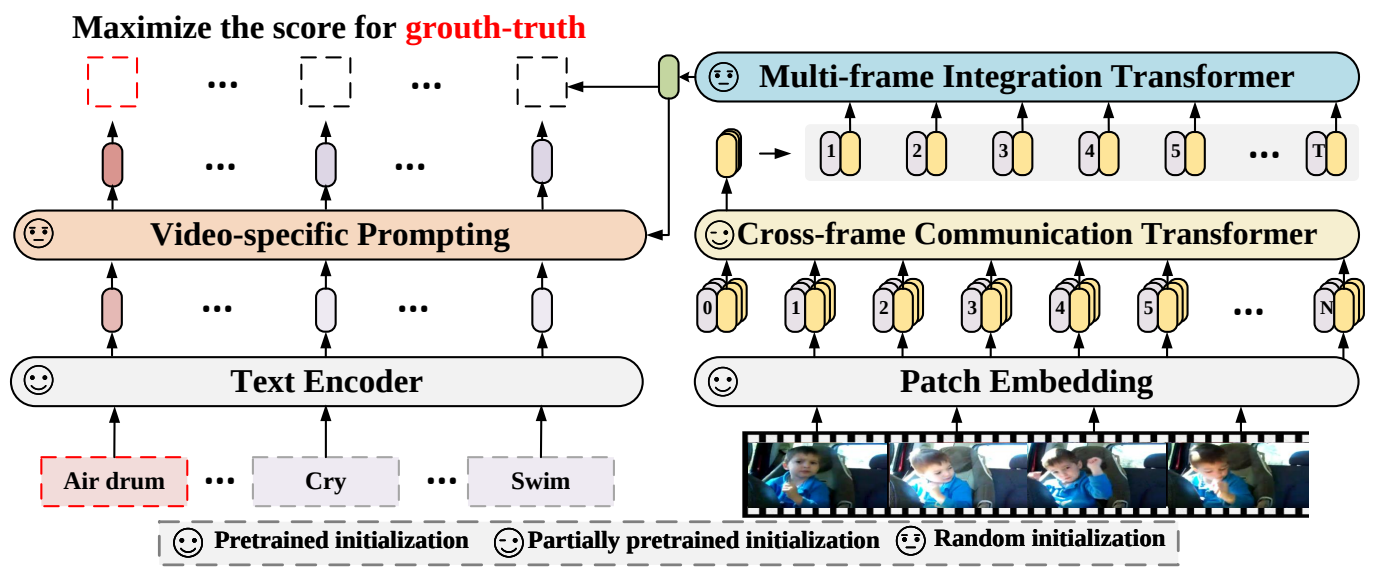
- Cross-frame communication transformer (CCT)
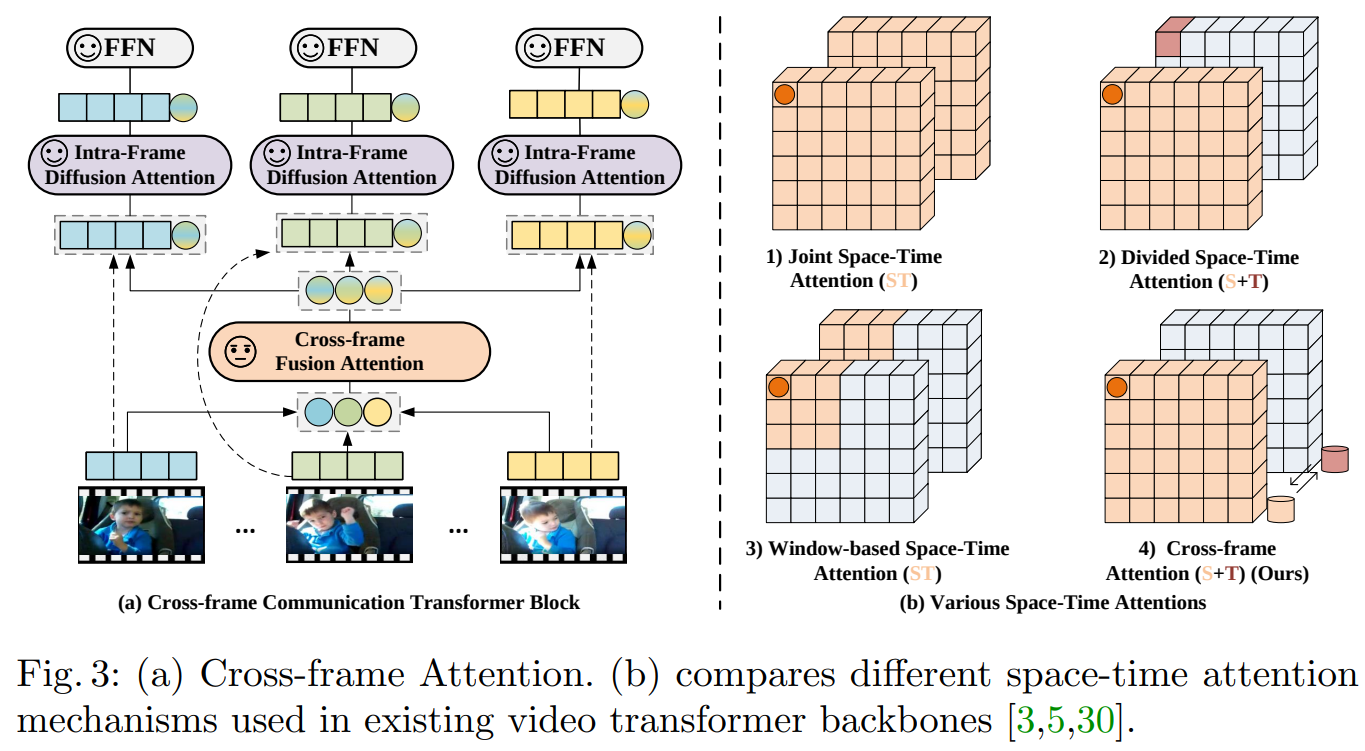
- Cross-frame fusion attention
- frame 간 information을 교환하기 위해 제안됨
- 각 frame별 patch embedding 후 각 frame의 [CLS] token 간 self-attention 수행
- 이후 입력 patch와 concatenation
- Intra-frame fusion attention
- frame 내부의 patch 간 information을 교환하기 위해 제안됨
- Concatenation된 patch 간 self-attention 수행
- 출력의 [CLS] token을 다음 과정으로 전달
- Cross-frame fusion attention
- Multi-frame integration transformer (MIT)
- frame-level representation을 video-level representation으로 변환하기 위해 제안됨
- ex) (Batch, Frame, Embedding) -> (Batch, Embedding) 차원축소
- 각 frame별 embedding을 token으로 self-attention 수행
- 출력의 [CLS] token을 video-level representation으로 사용
- frame-level representation을 video-level representation으로 변환하기 위해 제안됨
- Video-specific prompting scheme
- Video representation을 semantic labels에 융합하여 text prompting을 강화하기 위해 제안
- CLIP text encoder를 통해 추출된 text embedding을 query, MIT의 frame token별 출력을 key 및 value로 사용하여 cross-attention 수행
- 출력은 각 클래스별 text representation
- Maximize the score for GT
- 각 클래스별 text representation과 video representation을 normalize하고 내적하여 cosine similarity 계산
- 각 클래스별 similarity를 최종적인 출력으로 사용
Experiments
- Fully-supervised experiments
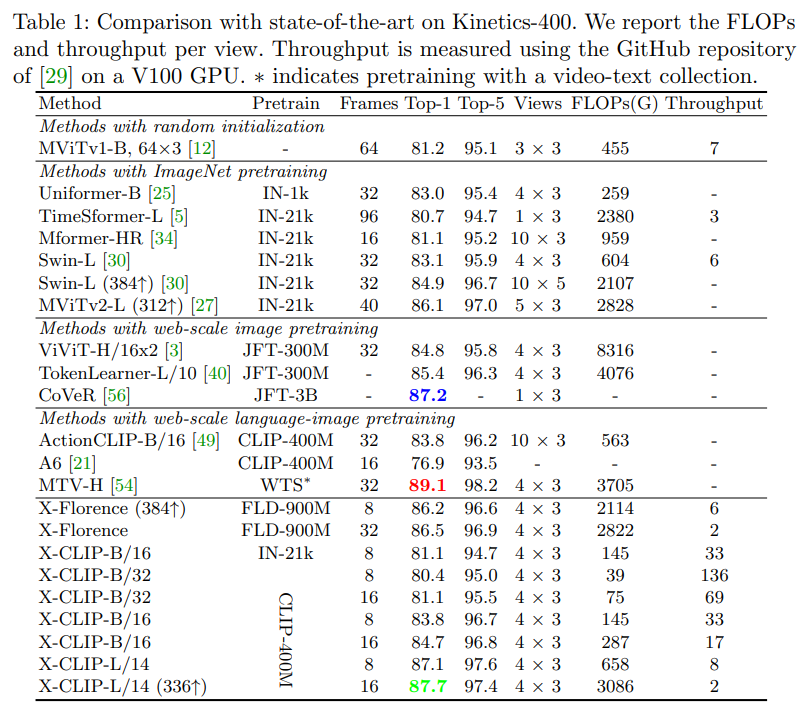
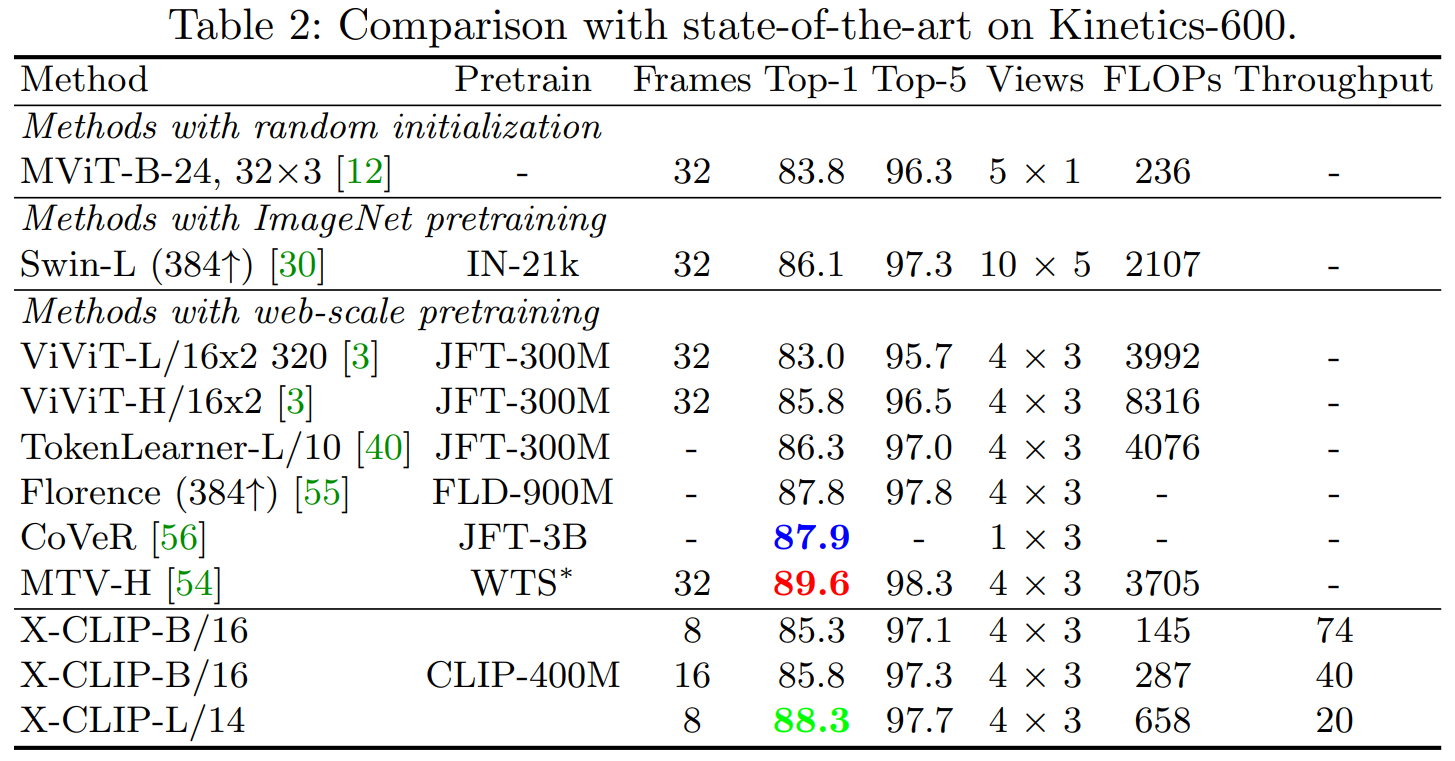
- 기본적인 fully-supervised 환경에서는 최고는 아니지만 괜찮은 성능을 보임
- Zero-shot experiments
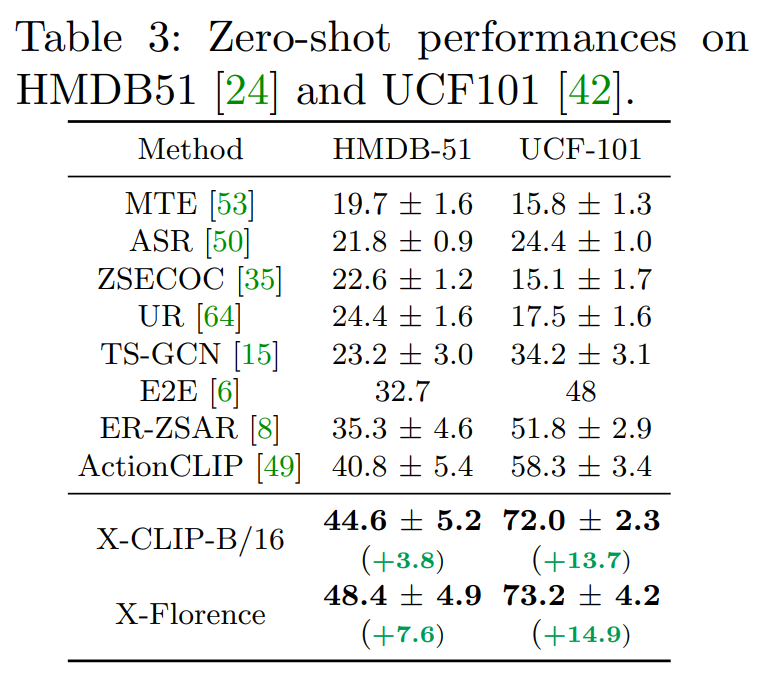
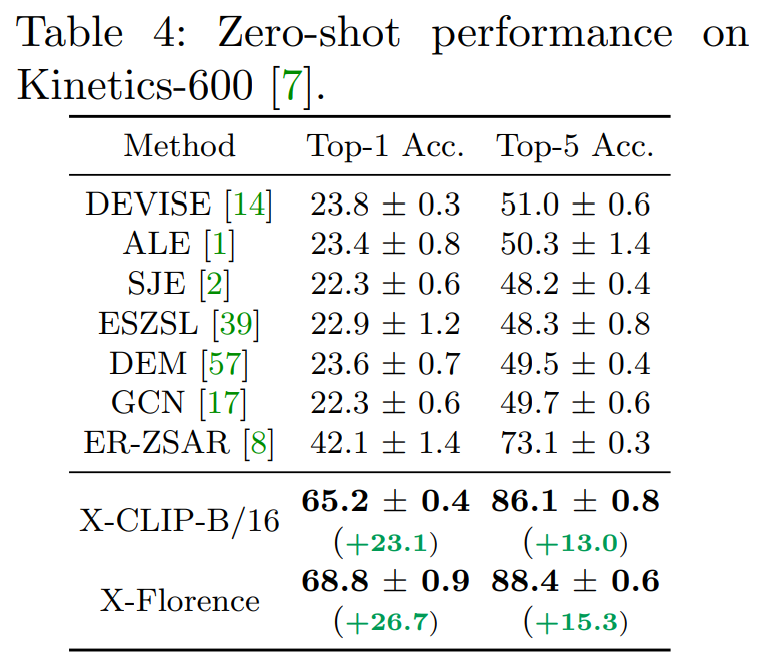
- 모델은 Kinetics-400으로 학습
- Zero-shot 환경에서는 이전 methods와 비교해서 아주 높은 차이를 보이며 최고 성능을 달성
- Few-shot experiments//
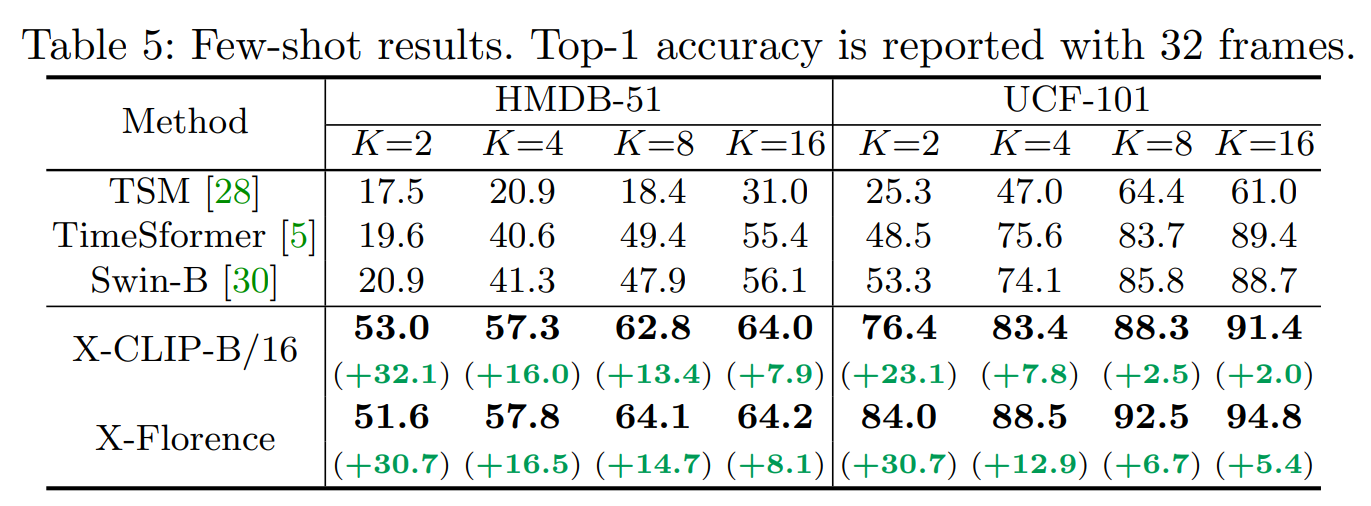
- Few-shot 환경에서도 이전 methods와 비교해서 아주 높은 차이를 보이며 최고 성능을 달성
Writer Comments
- 현재 X-CLIP보다 더 높은 모델인 VideoCoCa, MOV가 있으나 이는 구현이 불가능 (데이터셋 및 코드 미공개) 하므로 X-CLIP을 baseline으로 현재 연구를 진행중
{kind=link}